Pagkakaiba sa pagitan ng UMA at NUMA

Nilalaman

Ang mga Multiprocessors ay maaaring nahahati sa tatlong mga kategorya ng pagbabahagi ng memorya ng memorya - UMA (Uniform Memory Access), NUMA (Hindi pantay na Pag-access sa Memory) at COMA (Cache-only Memory Access). Ang mga modelo ay naiiba batay sa kung paano ipinamamahagi ang mga mapagkukunan ng memorya at hardware. Sa modelo ng UMA, ang pisikal na memorya ay pantay na ibinahagi sa mga processors na mayroon ding pantay na latency para sa bawat memorya ng memorya habang ang NUMA ay nagbibigay ng variable na pag-access ng oras para sa mga processors na ma-access ang memorya.
Ang bandwidth na ginamit sa UMA sa memorya ay pinaghihigpitan dahil gumagamit ito ng solong controller ng memorya. Ang pangunahing motibo ng pagdating ng mga makina ng NUMA ay upang mapagbuti ang magagamit na bandwidth sa memorya sa pamamagitan ng paggamit ng maraming mga Controller ng memorya.
-
- Tsart ng paghahambing
- Kahulugan
- Pangunahing Pagkakaiba
- Konklusyon
Tsart ng paghahambing
| Batayan para sa paghahambing | UMA | NUMA |
|---|---|---|
| Pangunahing | Gumagamit ng isang solong controller ng memorya | Maramihang mga controller ng memorya |
| Uri ng mga bus na ginamit | Single, maramihang at crossbar. | Puno at hierarchical |
| Oras ng pag-access ng memorya | Katumbas | Mga pagbabago ayon sa distansya ng microprocessor. |
| Angkop para sa | Pangkalahatang layunin at application ng pagbabahagi ng oras | Mga real-time at oras-kritikal na mga aplikasyon |
| Bilis | Mabagal | Mas mabilis |
| Bandwidth | Limitado | Higit sa UMA. |
Kahulugan ng UMA
UMA (Uniform Memory Access) system ay isang nakabahaging arkitektura ng memorya para sa mga multiprocessors. Sa modelong ito, ang isang solong memorya ay ginagamit at na-access ng lahat ng mga processors na iniharap ang multiprocessor system sa tulong ng interconnection network. Ang bawat processor ay may pantay na pag-access sa memorya (latency) at bilis ng pag-access. Maaari itong magamit ang alinman sa iisang bus, maramihang bus o switch ng crossbar. Dahil nagbibigay ito ng balanse na ibinahaging access sa memorya, kilala rin ito SMP (Symmetric multiprocessor) mga sistema.
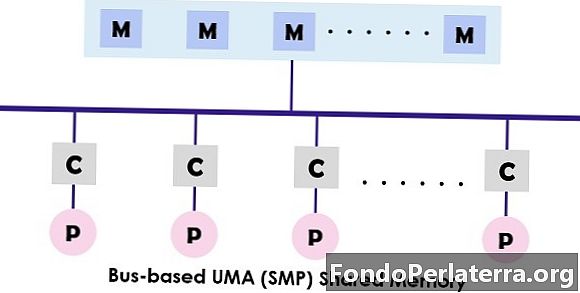
Ang tipikal na disenyo ng SMP ay ipinakita sa itaas kung saan ang bawat processor ay unang nakakonekta sa cache pagkatapos ay naka-link ang cache sa bus. Sa wakas ang bus ay konektado sa memorya. Ang arkitektura ng UMA na ito ay binabawasan ang pagtatalo para sa bus sa pamamagitan ng pagkuha ng mga tagubilin nang direkta mula sa indibidwal na nakahiwalay na cache. Nagbibigay din ito ng isang pantay na posibilidad para sa pagbabasa at pagsulat sa bawat processor. Ang mga tipikal na halimbawa ng modelo ng UMA ay mga Sun Starfire server, Compaq alpha server at HP v series.
Kahulugan ng NUMA
NUMA (Hindi pantay na Pag-access sa Memory) ay din isang multiprocessor modelo kung saan ang bawat processor na konektado sa nakalaang memorya. Gayunpaman, ang mga maliit na bahagi ng memorya ay pinagsama upang gumawa ng isang solong puwang ng address. Ang pangunahing punto upang pag-isipan dito ay hindi katulad ng UMA, ang oras ng pag-access ng memorya ay nakasalalay sa distansya kung saan inilalagay ang processor na nangangahulugang iba't ibang oras ng pag-access sa memorya. Pinapayagan nito ang pag-access sa alinman sa lokasyon ng memorya sa pamamagitan ng paggamit ng pisikal na address.
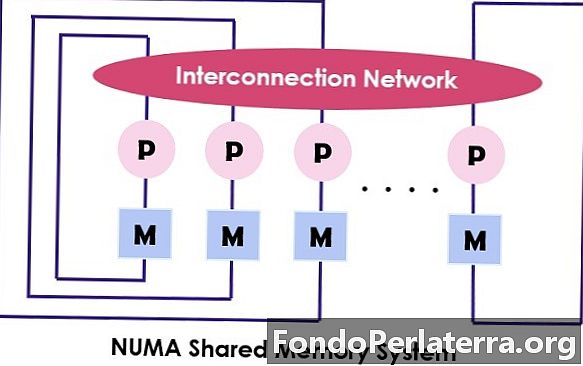
Tulad ng nabanggit sa itaas ng arkitektura ng NUMA ay inilaan upang madagdagan ang magagamit na bandwidth sa memorya at kung saan gumagamit ito ng maraming mga Controller ng memorya. Pinagsasama nito ang maraming mga cores ng makina sa "mga node"Kung saan ang bawat core ay may isang controller ng memorya. Upang ma-access ang lokal na memorya sa isang makina ng NUMA kinukuha ng pangunahing memorya ang pinamamahalaan ng memorya ng controller sa pamamagitan ng node nito. Habang ma-access ang malayuang memorya na hinahawakan ng iba pang memorya ng memorya, ang core s ang hiling ng memorya sa pamamagitan ng mga link na magkakaugnay.
Ang arkitektura ng NUMA ay gumagamit ng mga network ng puno at hierarchical bus upang maiugnay ang mga bloke ng memorya at ang mga processors. BBN, TC-2000, SGI Pinagmulan 3000, Cray ang ilan sa mga halimbawa ng arkitektura ng NUMA.
- Ang modelo ng UMA (ibinahaging memorya) ay gumagamit ng isa o dalawang mga controller ng memorya. Tulad ng laban, ang NUMA ay maaaring magkaroon ng maraming mga Controller ng memorya upang ma-access ang memorya.
- Ang solong, maramihang at crossbar busses ay ginagamit sa arkitektura ng UMA. Sa kabaligtaran, ang NUMA ay gumagamit ng hierarchical, at uri ng puno ng mga busses at koneksyon sa network.
- Sa UMA ang oras ng pag-access ng memorya para sa bawat processor ay pareho habang sa NUMA ang pagbabago ng pag-access ng memorya habang ang distansya ng memorya mula sa processor ay nagbabago.
- Pangkalahatang layunin at pagbabahagi ng oras na aplikasyon ay angkop para sa mga machine ng UMA. Sa kaibahan, ang naaangkop na aplikasyon para sa NUMA ay real-time at kritikal na oras-kritikal.
- Ang mga magkaparehong nakabatay sa system na kahanay ay gumagana nang mas mabagal kaysa sa mga sistemang NUMA.
- Pagdating sa bandwidth UMA, may limitadong bandwidth. Sa kabilang banda, ang NUMA ay may bandwidth higit pa sa UMA.
Konklusyon
Ang arkitektura ng UMA ay nagbibigay ng parehong pangkalahatang latency sa mga nagproseso ng pag-access sa memorya. Ito ay hindi masyadong kapaki-pakinabang kapag ang lokal na memorya ay na-access dahil ang latency ay magiging uniporme. Sa kabilang banda, sa NUMA ang bawat processor ay may nakalaang memorya na nag-aalis ng latency kapag na-access ang lokal na memorya. Ang latency ay nagbabago bilang distansya sa pagitan ng processor at mga pagbabago sa memorya (i.e., Non-uniporme). Gayunpaman, napabuti ng NUMA ang pagganap kumpara sa arkitektura ng UMA.





